강의복습
1. Instance/Panoptic segmentation
더보기
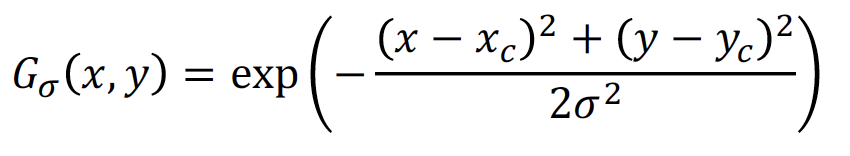

1) Instance segmentation
- Instance segmentation = Semantic segmentation + distinguishing instances
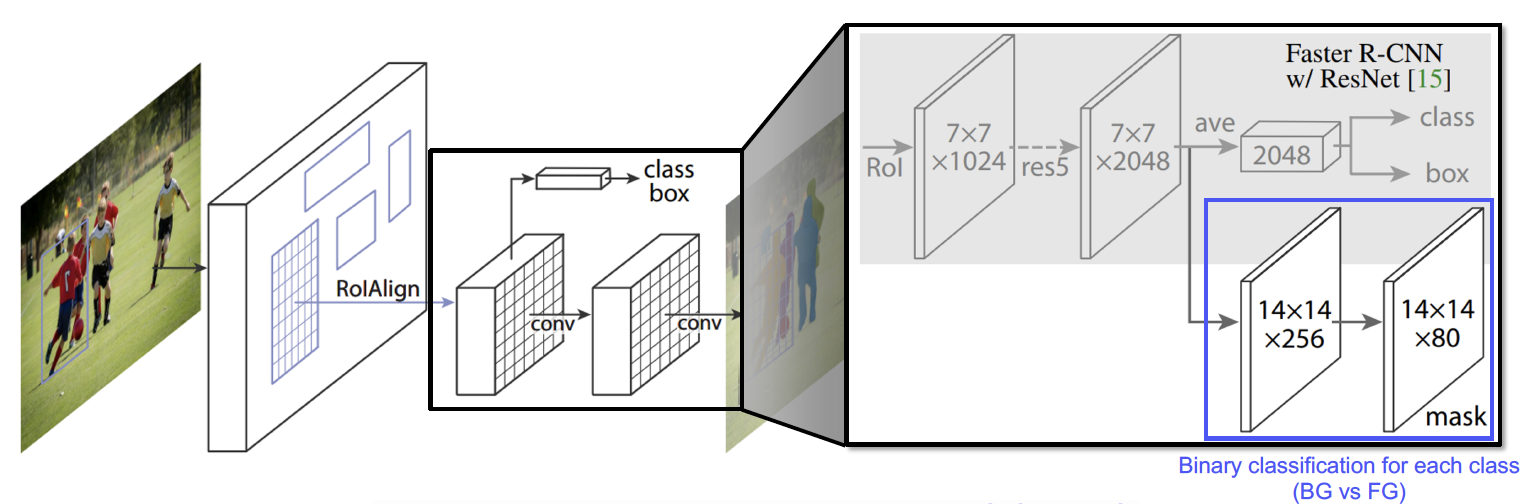
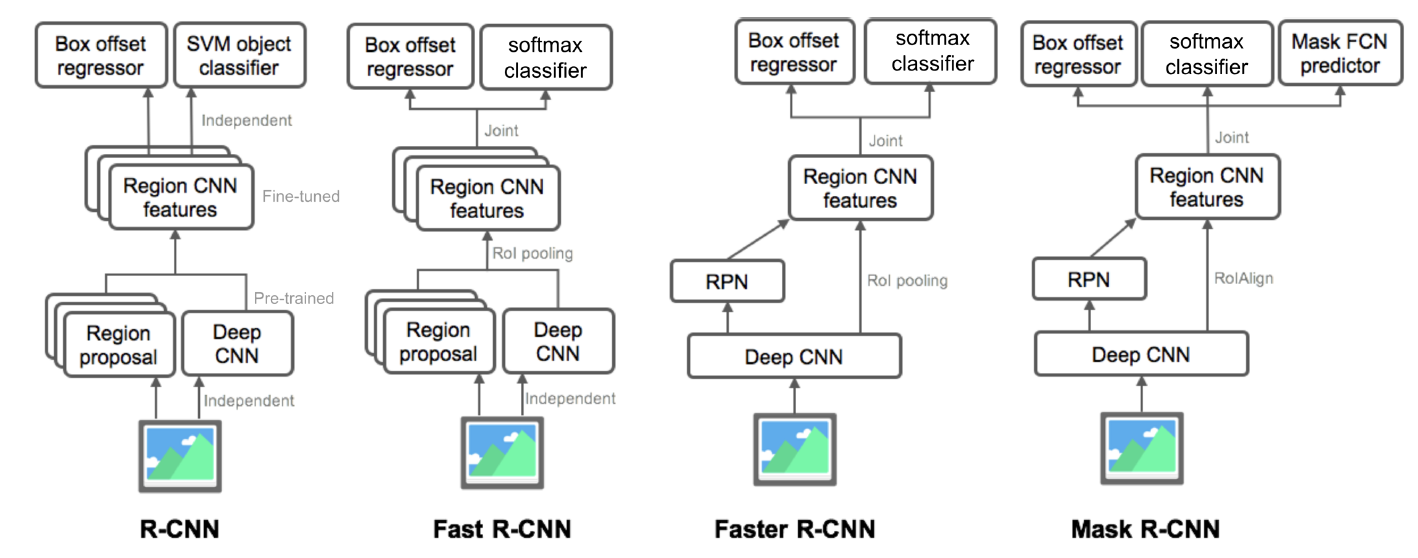
- Mask R-CNN
- FasterR-CNN+Mask branch
- RoIAlign: 소수점 픽셀까지 정교하게 계산
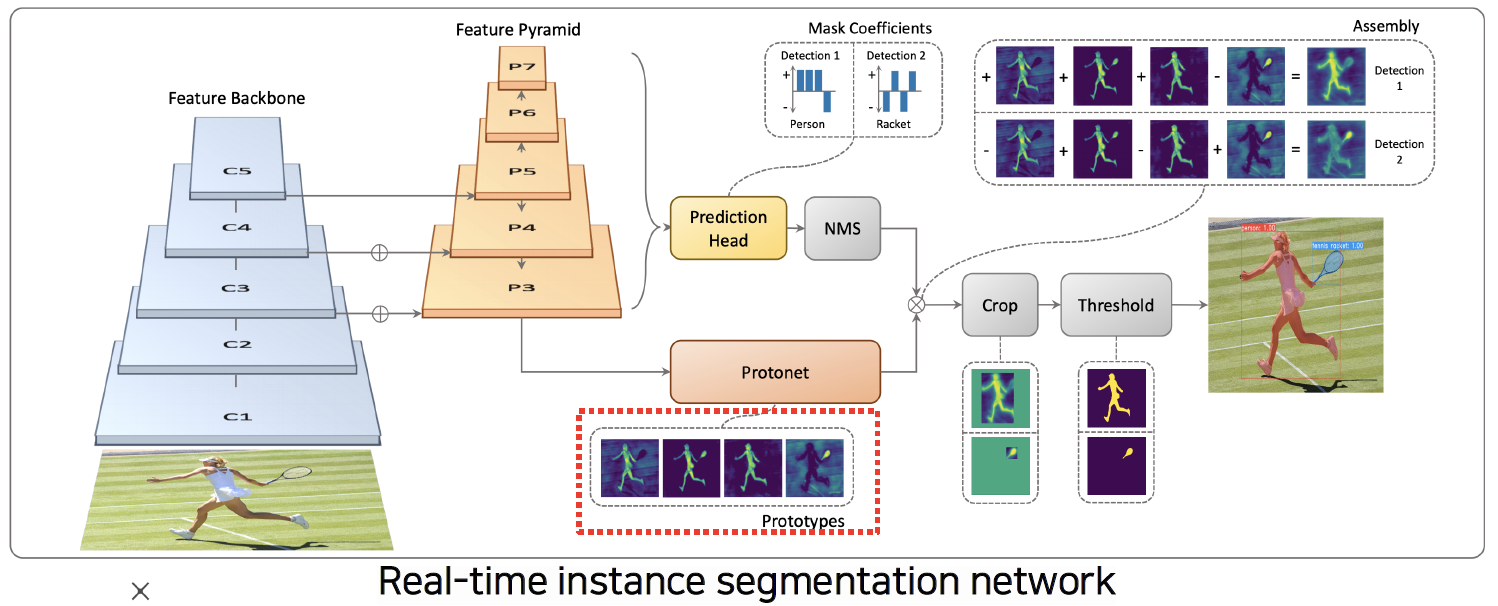
- YOLACT(You Only Look At CoefficientTs)
- Prototypes: mask를 합성할 수 있는 재료들
- 적은 개수의 prototypes의 선형결합으로 다양한 mask 생성
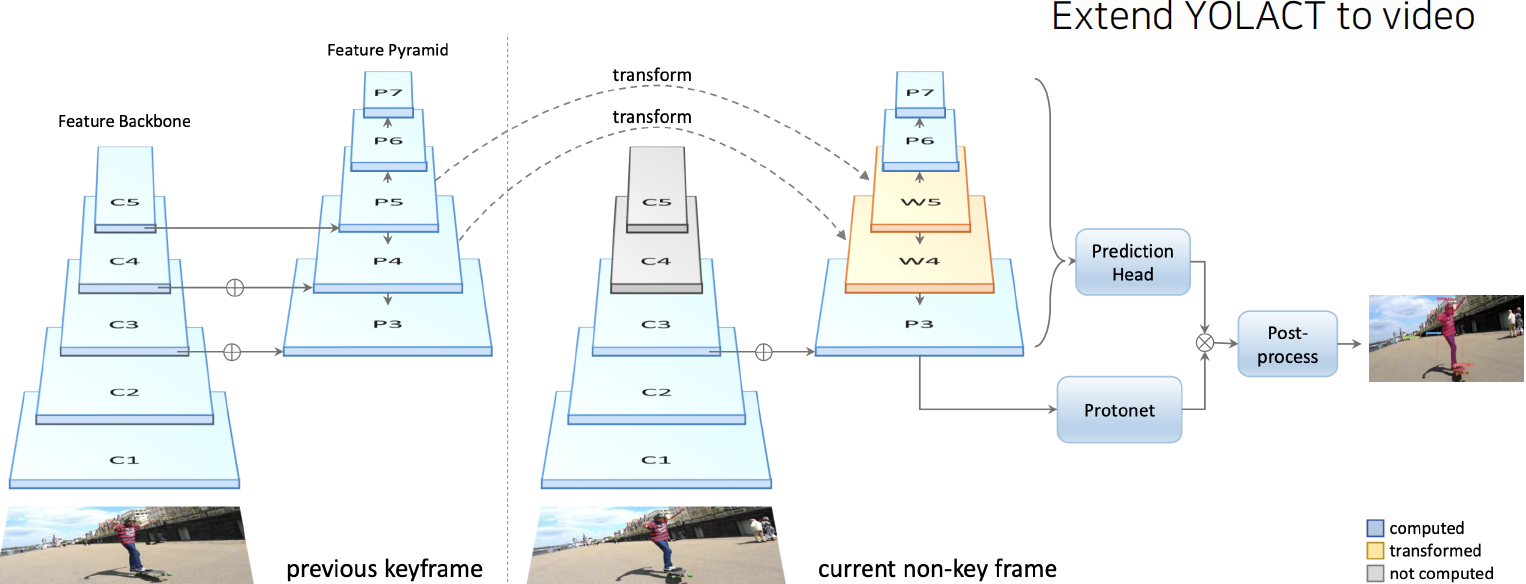
- YolactEdge: video로 확장
2) Panoptic segmentation
- Semantic segmentations: Stuff(배경 관련) + Things(배경 제외)
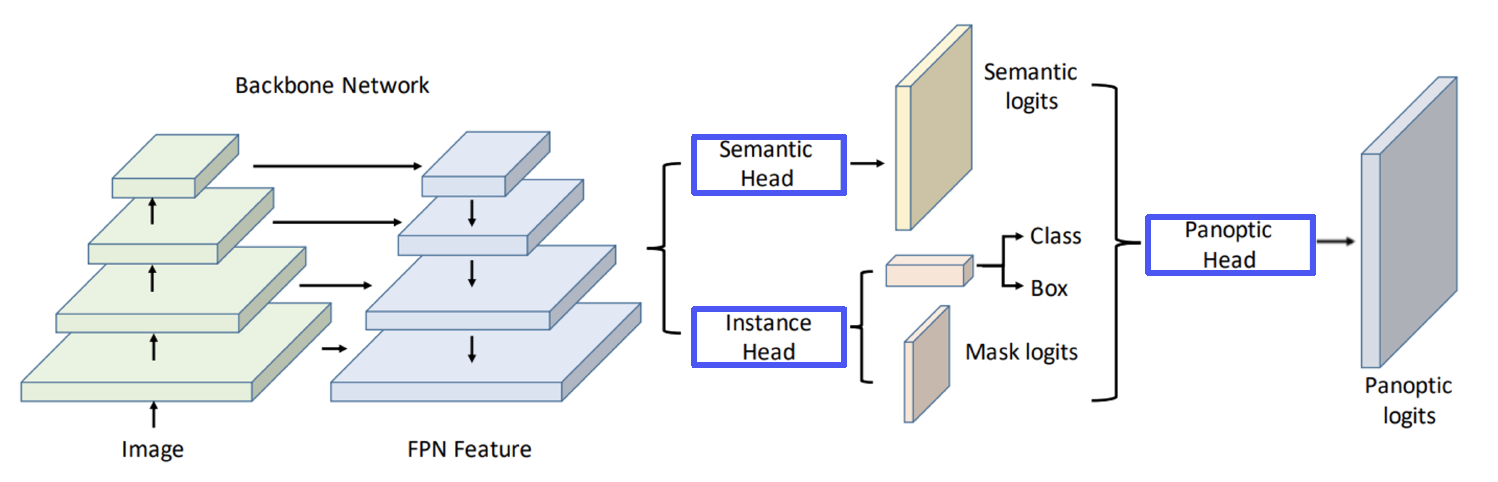
Panoptic segmentation: Stuff + Instance of Things - UPSNet
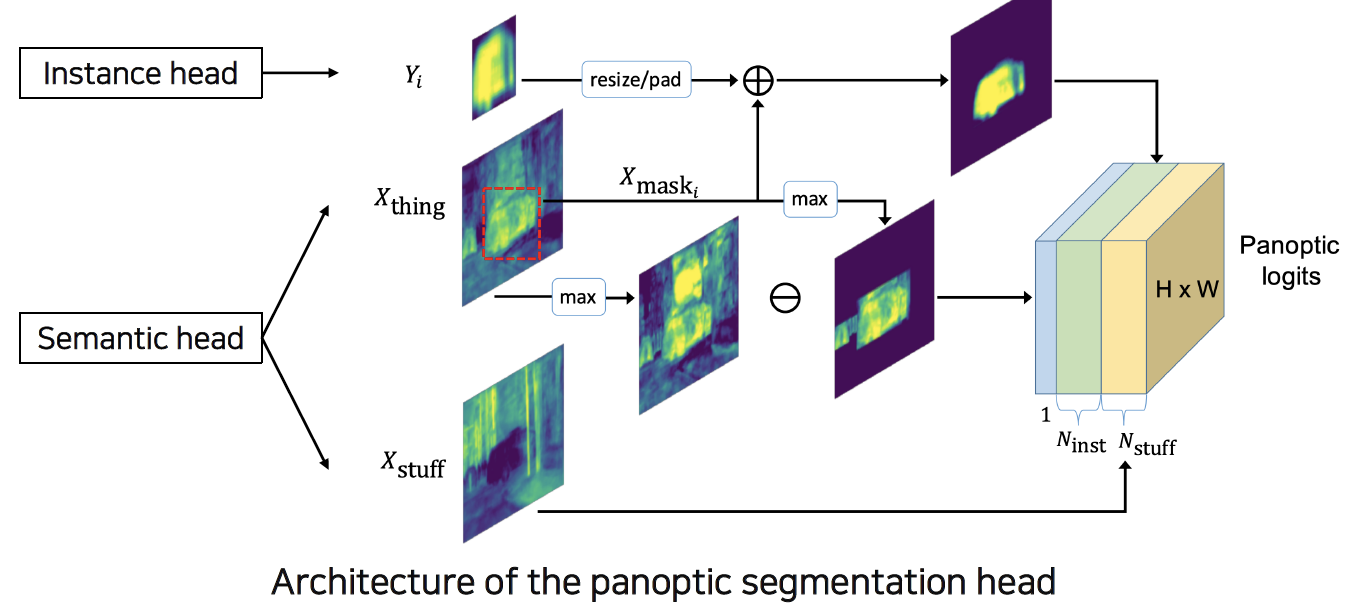
- Semantic & Instance head → Panoptic head → Panoptic logits
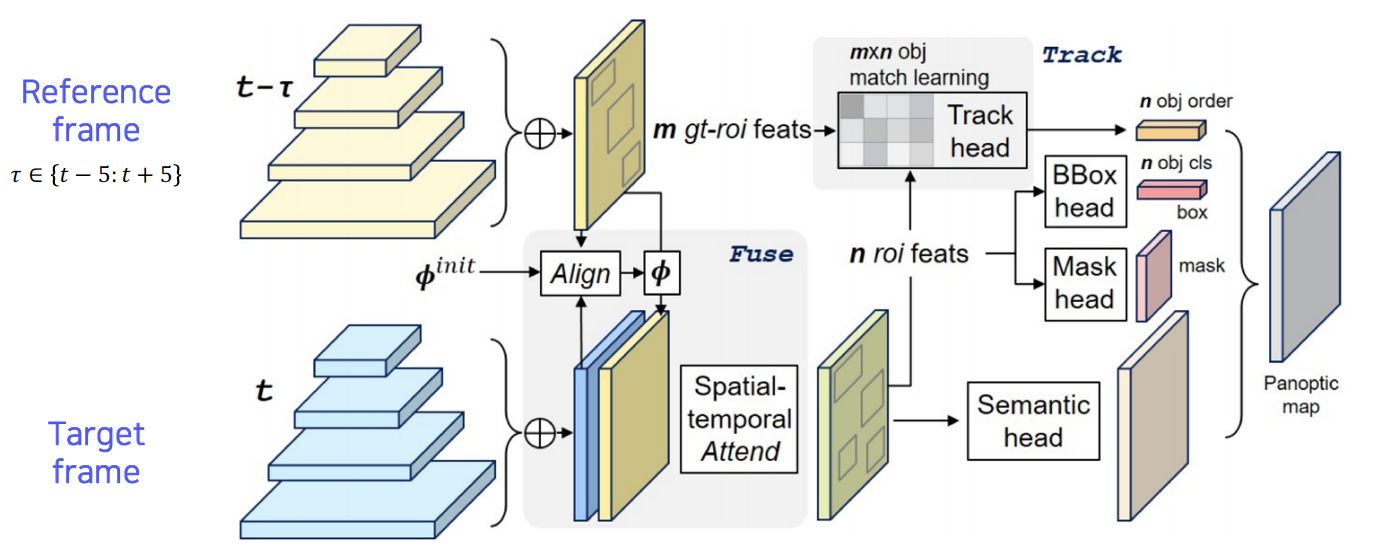
- VPSNet: For Video
- Align reference features onto the target feature map (Fusion at pixel level)
- Track module associates different object instances (Track at instance level)
- Fused-and-tracked modules are trained to synergize each other
3) Landmark localization
- 중요한 특징 부분들을 정의하고 추적 (keypoint estimation)
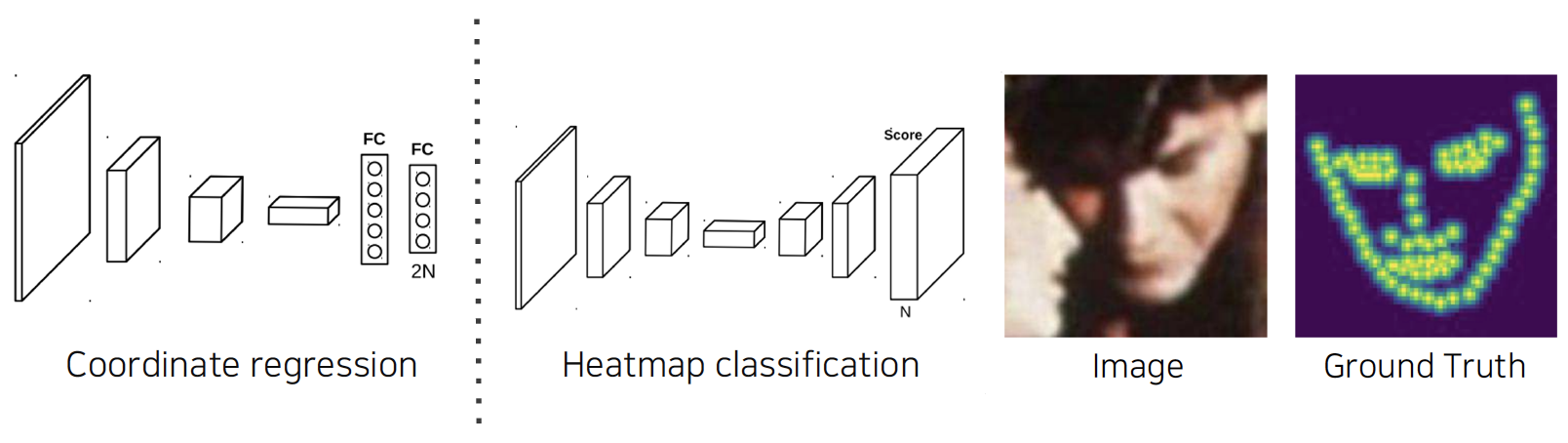
- Coordinate regression: landmark가 N개일 때 각 포인트의 x,y 위치(2N개) 예측하는 방법, inaccurate & biased
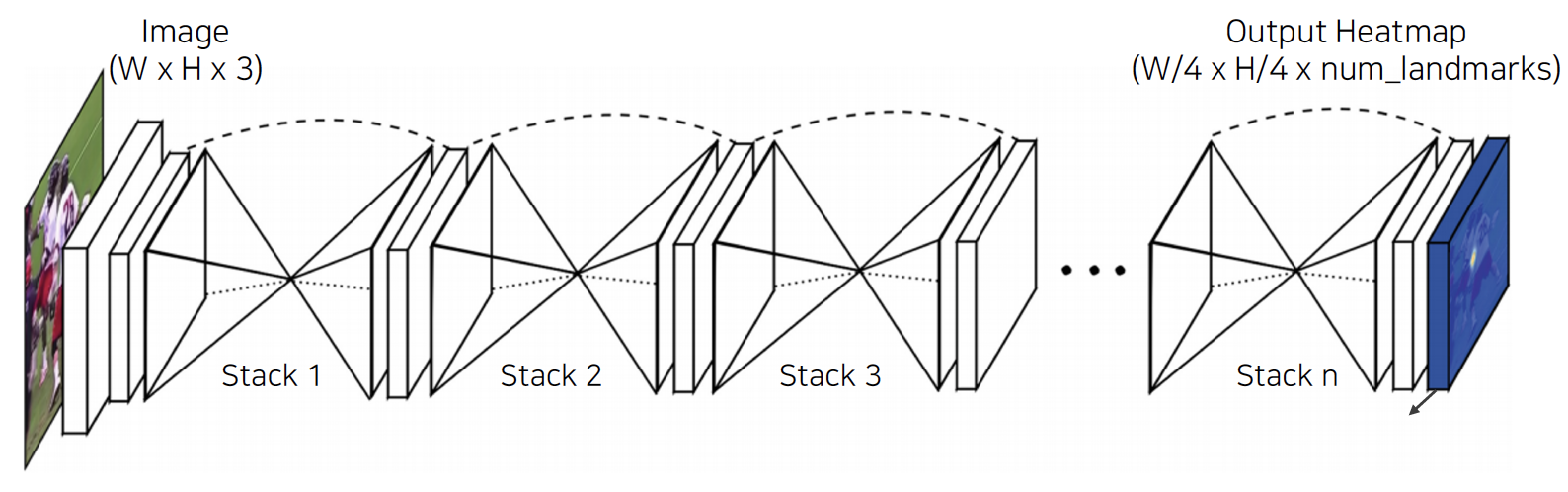
Heatmap classification: 각 키포인트마다 확률맵을 픽셀별로 표현, 정확하지만 계산량 많아짐
- Gaussian heatmap
- Hourglass network
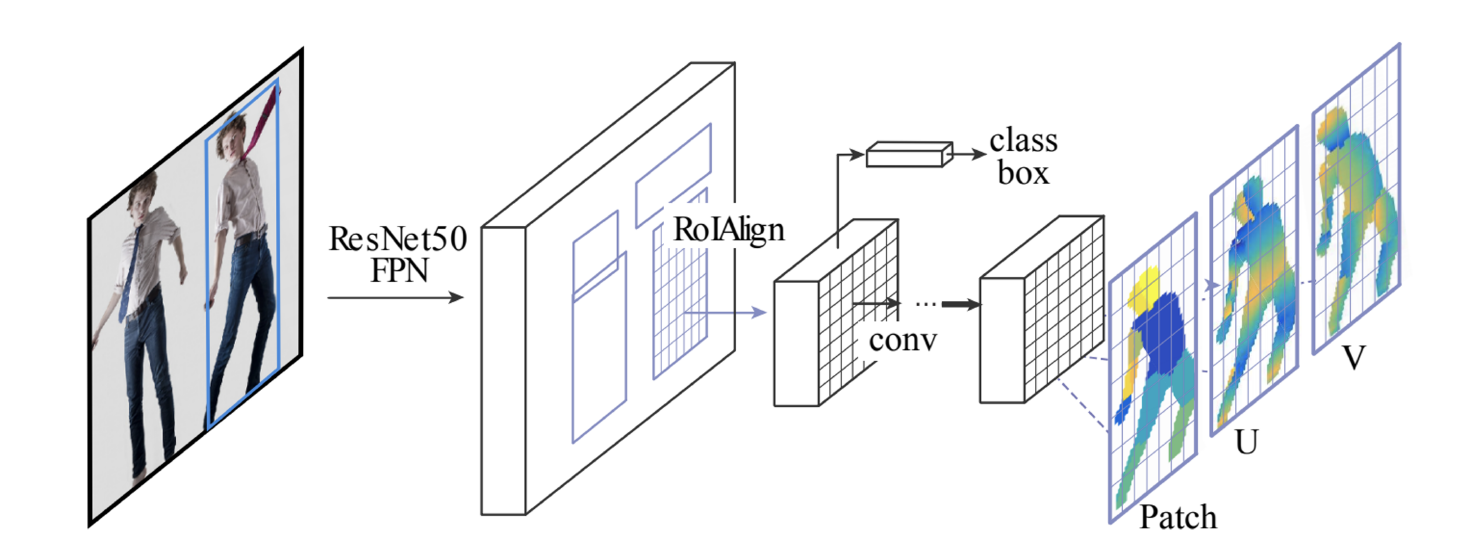
- DensePose
- Faster R-CNN + 3D surface regression branch
- UV map: 3D mesh 표현
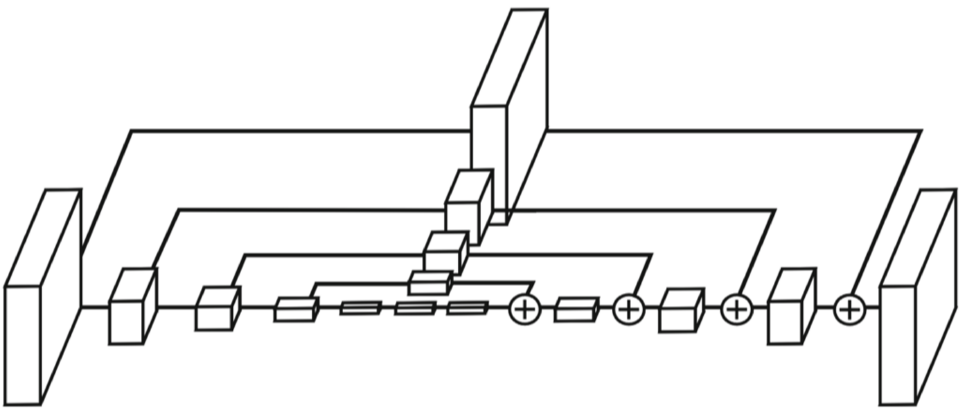
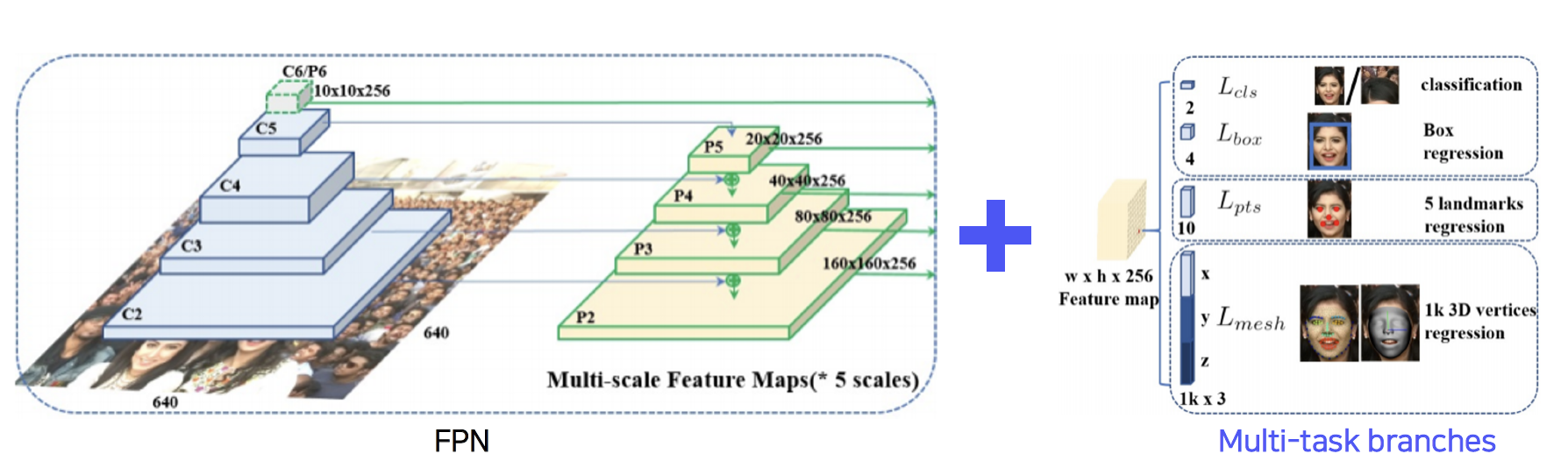
- RetinaFace: FPN + Multi-task branches
- Extension pattern: FPN + Target-task branches
4) Detecting objects as keypoints
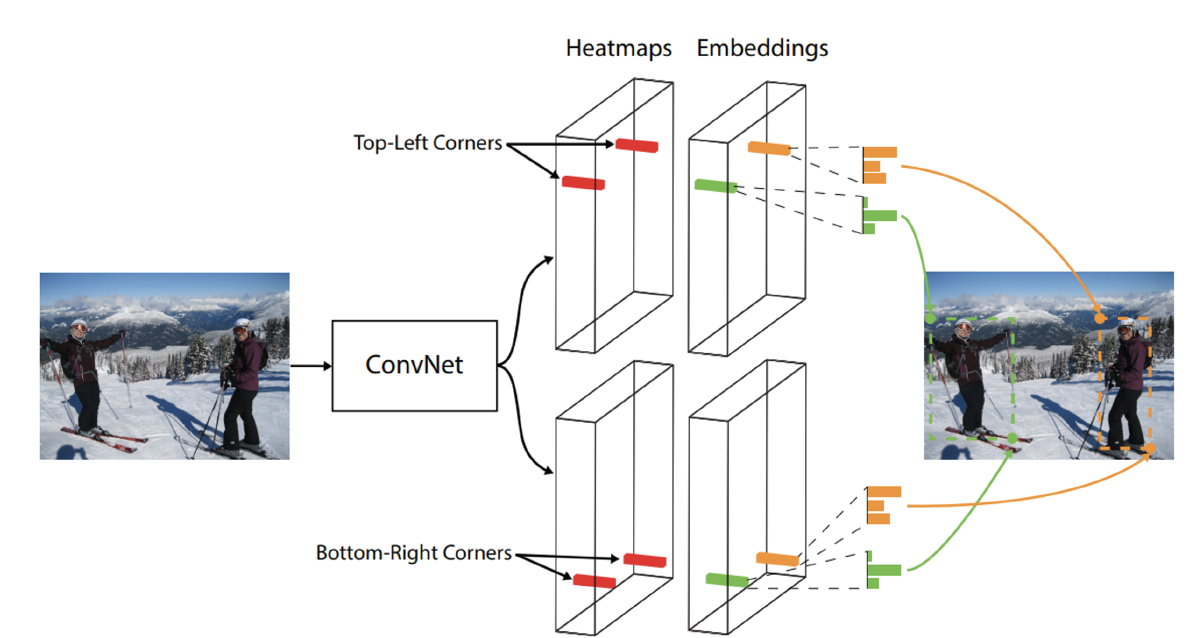
- CornerNet
- Bounding box: {Top-left, Bottom-right} corners
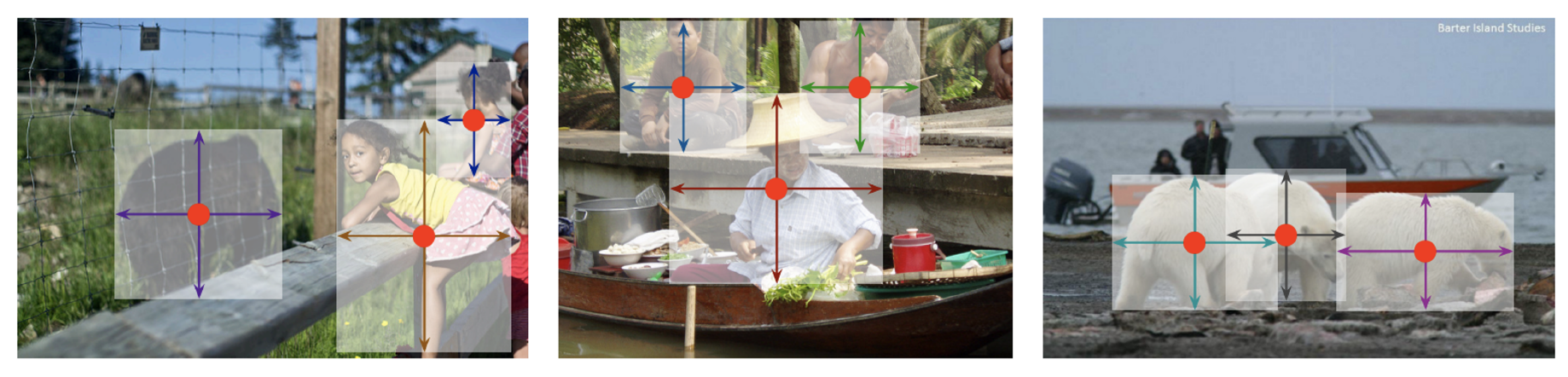
- CenterNet
- Bounding box: {Top-left, Bottom-right, Center} points
- Bounding box: {Width, Height, Center} points
2. Conditional generative model
더보기
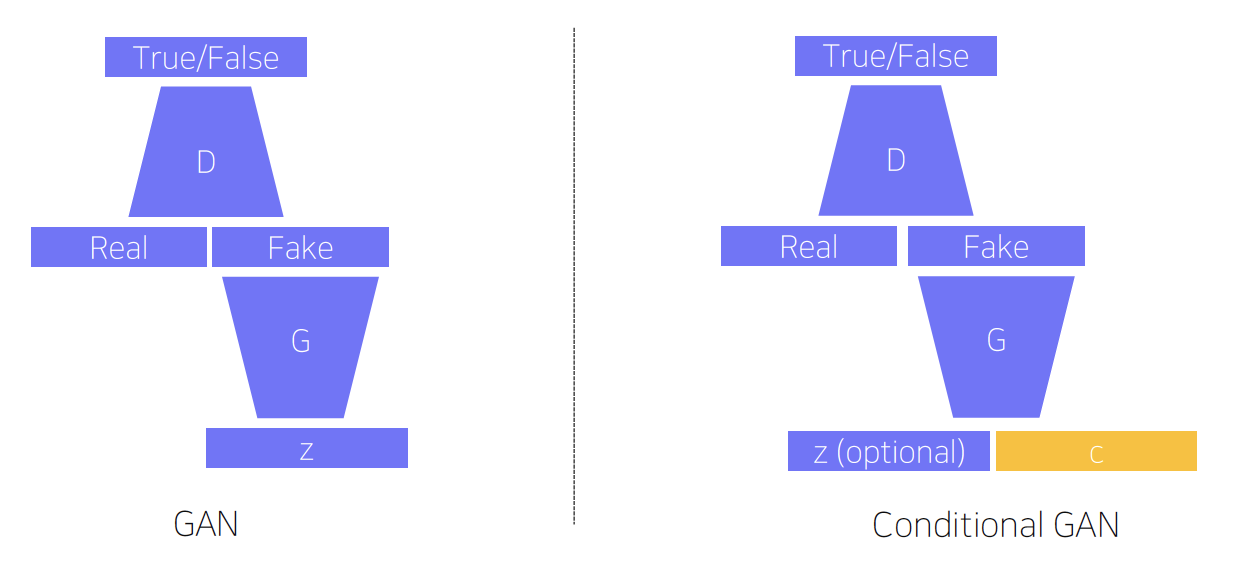

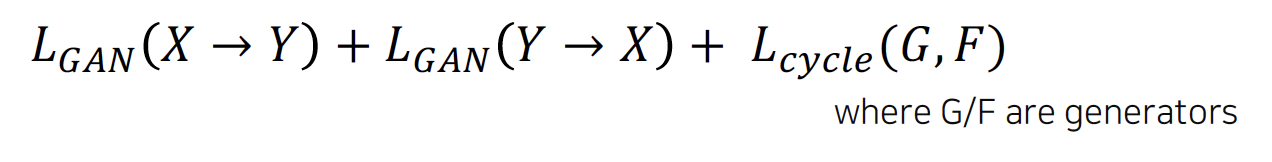



1) Conditional generative model
- Conditional generative model: 주어진 조건에서 random sample 생성
- audio super resolution, machine translation, article generation with the title 등
- Conditional GAN and image translation
- Image-to-image translation: Style transfer, Super resolution, Colorization 등
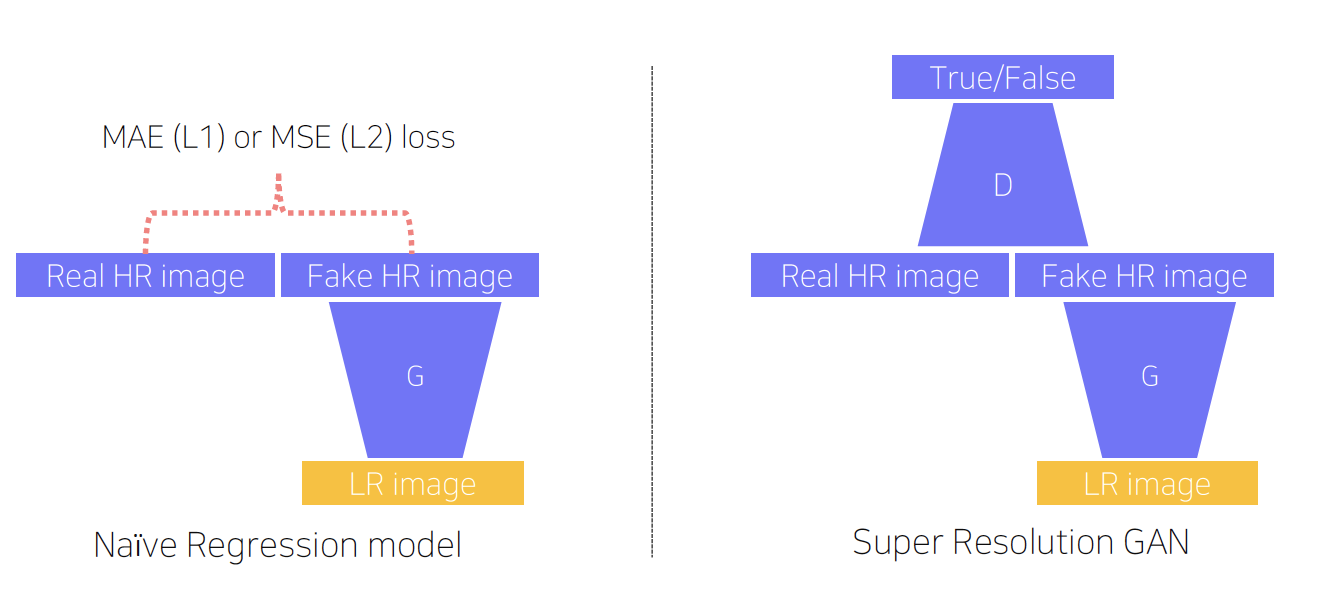
- Example of Conditional GAN: Super resolution
- Input: low resolution image
Output: High resolution image - MAE/MSE: pixel intensity difference 측정, 여러 패치들 존재
GAN loss: 진짜처럼 보이는지 아닌지 비교 - 실제 이미지가 검은색, 흰색 2가지 색밖에 없을 때
L1 loss: 회색 output 생성
GAN loss: 검은색 또는 흰색 output 생성 - SRGAN(GAN loss for Super Resolution)
- Input: low resolution image
2) Image translation GANs
- Pix2Pix: Translating an image to a corresponding image in another domain (e.g. style)
- CycleGAN: enables the translation between domains with non-pairwise datasets
- GAN loss: translation (X→Y, Y→X)
- Cycle-consistency loss: preserve contents (self-supervision)
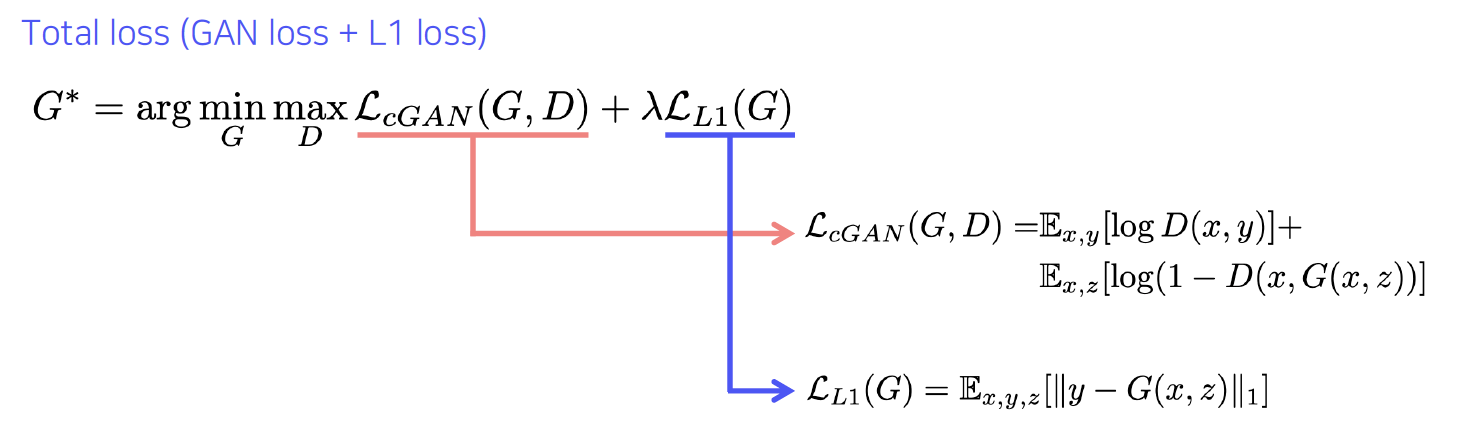
- CycleGAN loss = GAN loss (in both direction) + Cycle-consistency loss
- Perceptual loss
- 코드 작성 및 학습 쉬움 (simple forward & backward computation)
- pre-trained network 필요
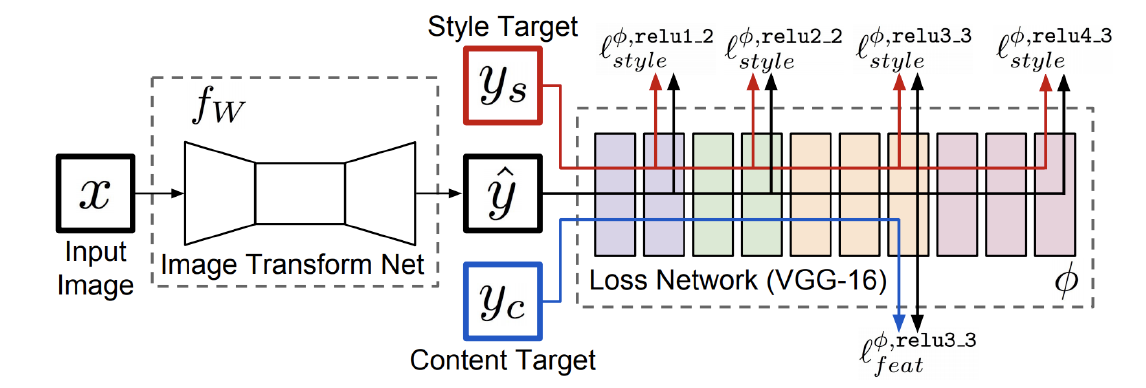
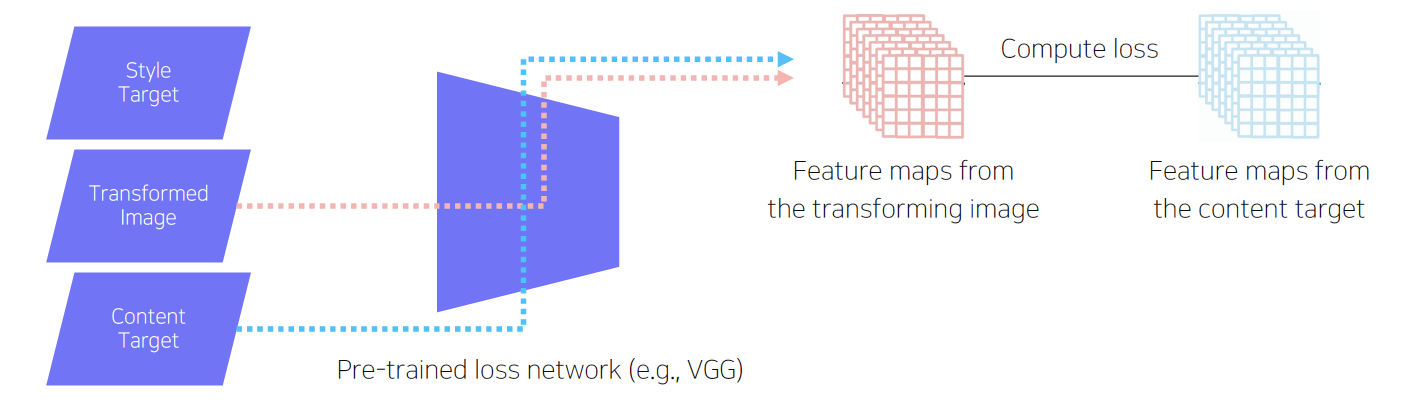
- Image Transform Net: transformed image 출력
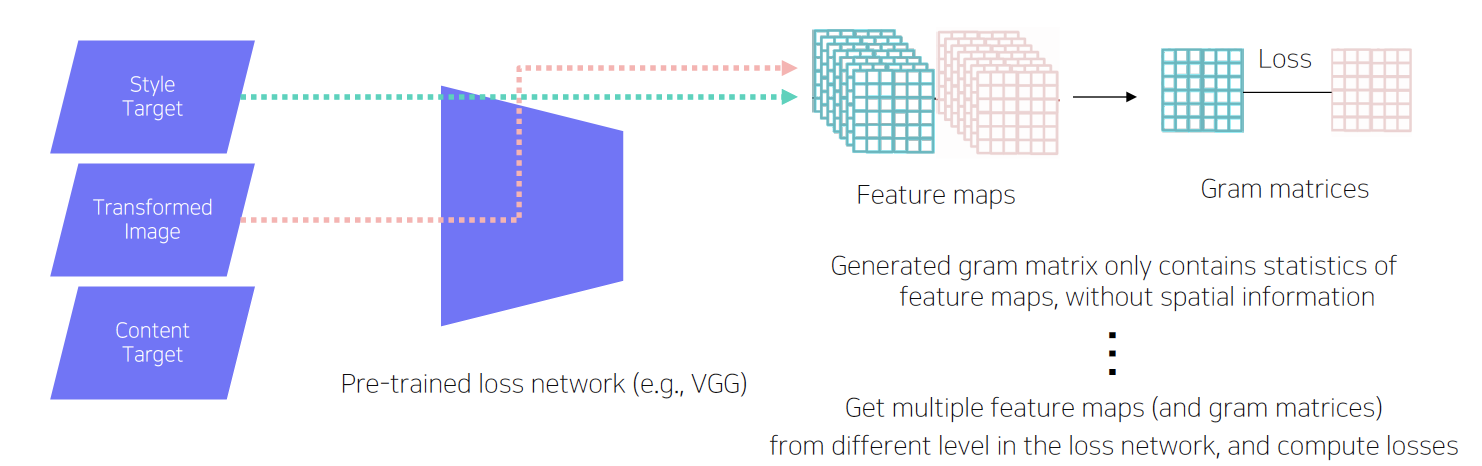
- Loss Network: style & feature loss 계산, 주로 VGG 모델 사용
- Feature reconstruction loss: output과 target image의 feature map의 L2 loss 계산
Style reconstruction loss: featurer map으로부터 생성된 gram matrices의 L2 loss 계산
3) Various GAN applications
- Deepfake
- Face de-identification
- Video translation
코멘트
오늘은 여러가지 segmentation 및 생성 모델에 대해 배웠다. 깊게 파고들면 너무 어려울 것 같아서 그냥 이런 것들도 있구나 하고 넘어갔다.
'부스트캠프 AI Tech 1기 [T1209 최보미] > U stage' 카테고리의 다른 글
| Day36 학습정리 - 모델경량화1 (0) | 2021.03.15 |
|---|---|
| Day35 학습정리 - CV5 (0) | 2021.03.12 |
| Day33 학습정리 - CV3 (0) | 2021.03.10 |
| Day32 학습정리 - CV2 (0) | 2021.03.09 |
| Day31 학습정리 - CV1 (0) | 2021.03.08 |