강의복습
1. Image classification II
더보기
1) Problems with deeper layers
- Gradient vanishing / exploding
- Computationally coomplex
- Degradation
2) CNN architectures for image classification 2
- GoogLeNet
- 채널 개수 줄이기 위해 1×1 convolution 적용
- Stem network
- Stacked inception modules
- Auxiliary classifiers
- Classifier output (a single FC layer)
- ResNet
- Degradation 문제 해결하기 위해 Shortcut connection 적용
- 기타
- DenseNet
- SENet
- EfficientNet
- Deformable convolution
3) Summary of image classification
- AlexNet
- Simple CNN architecture
- Simple computation, but heavy memory size
- Low accuracy
- VGGNet
- simple with 3×3 convolutions
- Highest memory, the heaviest computation
- GoogLeNet
- inception module and auxiliary classifier
- ResNet
- deeper layers with residual blocks
- Moderate efficiency(depending on the model)
- Backbone model: 주로 VGGNet 또는 ResNet이 사용됨
2. Semantic segmentation
더보기






1) Semantic segmentation
- 이미지의 각 픽셀을 카테고리로 분류
2) Semantic segmentation architectures
- Fully Convolutional Networks(FCN)
- first end-to-end architecture for semantic segmentation
- Fully connected layer: fixed dimensional vector 출력, 위치정보 버림 (Image classification)
Fully convolutional layer: classification map 출력 (Semantic segmentation) - 1×1 convolution layer의 한계: 해상도 매우 낮음
→upsampling으로 해결 - Upsampling: 작아진 이미지를 input image 크기로 복원 (참고: ronjian.github.io/blog/2018/03/23/CNN)
| Transposed convolution |
Upsample and convolution |
 |
 |
|
Checkerboard artifacts |
overlap issue 피함 Nearest-neighbor(NN) / Bilinear interpolation → convolution |
- skip connection (참고: modulabs-biomedical.github.io/FCN)
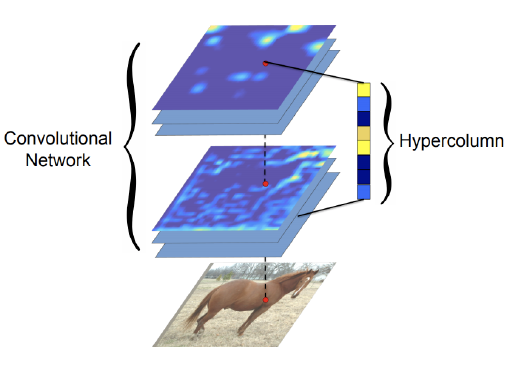
- Hypercolumns for object segmentation
- Hypercolumn: stacked vector of all CNN units on that pixel
- FCN과 유사한 구조 (차이점: 각 bounding box마다 적용)
- U-Net
- Contracting Path: 3×3 convolution 계속 적용, feature channel × 2, feature map 크기 × 1/2
Expanding Path: 2×2 convolution 계속 적용, feature channel × 1/2, feature map 크기 × 2 - input, feature size 짝수여야 함
- Contracting Path: 3×3 convolution 계속 적용, feature channel × 2, feature map 크기 × 1/2
- DeepLab
- Conditional Random Fields (CRFs)
- 1st row: score map (before softmax)
- 2nd row: belief map (after softmax)
- Conditional Random Fields (CRFs)
코멘트
오늘 피어세션에서 팀원분들이 나는 미처 생각 못했던 좋은 질문들을 많이 하셔서 나도 앞으로 공부할 때 대충 넘기지 말고 더 꼼꼼하게 해야겠다고 생각했다.
'부스트캠프 AI Tech 1기 [T1209 최보미] > U stage' 카테고리의 다른 글
| Day34 학습정리 - CV4 (0) | 2021.03.11 |
|---|---|
| Day33 학습정리 - CV3 (0) | 2021.03.10 |
| Day31 학습정리 - CV1 (0) | 2021.03.08 |
| Day30 학습정리 - AI + ML과 Quant Trading & AI Ethics (0) | 2021.03.05 |
| Day29 학습정리 - NLP를 위한 언어 모델의 학습, 평가 & AI와 저작권법 (0) | 2021.03.04 |