강의 복습
1. pandas II
더보기
1) Groupby
- SQL groupby 명령어와 같음
- split → apply → combine 과정 거쳐서 연산
- groupby 명령의 결과물도 dataframe
- df.groupby(기준컬럼)[적용컬럼]
- 한 개 이상의 column: df.groupby([column1, column2, ...])[적용컬럼]
- hierarchical index
- 두 개의 column으로 groupby를 할 경우 index 두 개 생성
- unstack(): group으로 묶여진 데이터를 matrix 형태로 전환
- swaplevel(): index level 변경
- operations: index level 기준으로 기본 연산 수행 가능(sum 등)
- groupby에 의해 split된 상태를 tuple 형태로 추출 가능
- get_group(): 특정 키값을 가진 그룹의 정보만 추출
- 추출된 group 정보에는 3가지 유형의 apply 가능
- Aggregation: 요약된 통계정보 추출 (grouped.agg())
- Transformation: 해당 정보를 변환, series 데이터에 적용되는 것 이외에는 key별로 요약된 정보 아님 (grouped.transform())
- Filtration: 특정 조건으로 데이터 검색 (grouped.filter())
2) Pivot table & Crosstab
- 엑셀의 pivot table과 동일
- index 축은 groupby와 동일
- column에 추가로 labeling 값 추가하여 value에 numeric type 값을 aggregation함
- crosstab
- 두 컬럼에 교차 빈도, 비율, 덧셈 등 구할 때 사용
- pivot table의 특수한 형태
- user-item rating matrix 등을 만들 때 사용 가능
3) Merge & Concat
- merge: SQL에서 많이 사용하는 Merge와 같은 기능, 두 개의 데이터를 하나로 합침
- pd.merge(df1, df2, on="column명", how="join method")
- 두 dataframe column 이름이 다를때: on 대신 left_on, right_on 사용
- join method
- inner join: left ∩ right (교집합)
- full(outer) join: left ∪ right (합집합)
- left join: left만
- right join: right만
- index based join: pd.merge(df1, df2, right_index=True, left_index=True)
- concat: 같은 형태의 데이터를 붙이는 연산작업
4) Persistence
- data loading시 db connection 기능 제공
- XLS persristence
- Dataframe의 엑셀 추출 코드,
- Xls 엔진으로 openpyxls 또는 XlsxWrite 사용
- Pickle persistence:
- 가장 일반적인 파이썬 파일 persistence,
- to_pickle, read_pickle 함수 사용
2. 확률론 맛보기
더보기
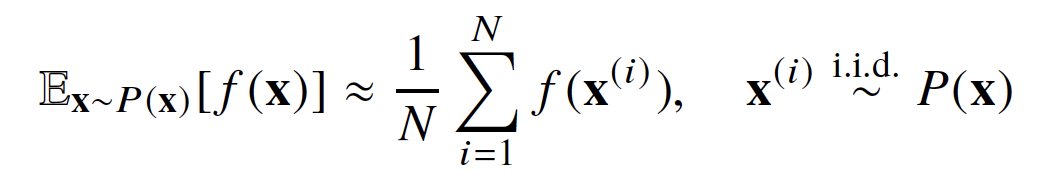
1) 딥러닝과 확률론
- 딥러닝은 확률론 기반의 기계학습 이론에 바탕을 두고 있음
- 기계학습에서 손실함수(loss function)들의 작동 원리는 데이터 공간을 통계적으로 해석해서 유도
- 회귀분석에서 L2-norm은 예측오차의 분산을 가장 최소화하는 방향으로 학습하도록 유도
- 분류 문제에서 사용되는 교차엔트로피(cross-entropy)는 모델 예측의 불확실성을 최소화하는 방향으로 학습하도록 유도
2) 확률분포
- 데이터공간: 𝒳 x 𝒴라 표기, 𝒟: 데이터공간에서 데이터를 추출하는 분포
- 데이터: 확률변수로 (x, y) ~ 𝒟라 표기
- 확률변수는 확률분포에 따라 이산형(discrete)과 연속형(continuous)으로 구분
- 이산형 확률변수: 확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링
- 연속형 확률변수: 데이터 공간에 정의된 확률변수의 밀도 위에서의 적분을 통해 모델링
- P(x): 입력 x에 대한 주변확률분포, y에 대한 정보를 주진 않음
3) 조건부확률
- P(x|y): 입력 x와 출력 y 사이의 관계를 모델링
- P(y|x): 입력변수 x에- 대해 정답이 y일 확률을 의미, 연속확률분포의 경우 밀도로 해석
- 로지스틱 회귀에서 사용했던 선형모델과 소프트맥스 함수의 결합은 데이터에서 추출된 패턴을 기반으로 확률을 해석하는데 사용
- 분류 문제에서 softmax(W𝜙 + b):데이터 x로부터 추출된 특징패턴 𝜙(x)과 가중치행렬 W를 통해 조건부확률 P(y|x) 계산
- 회귀 문제의 경우 조건부기대값 E[y|x] 추정
- 기대값(expectation): 데이터를 대표하는 통계량, 기대값을 이용해 분산, 첨도, 공분산 등 다른 여러 통계량 계산 가능
- 딥러닝은 다층신경망을 사용하여 데이터로부터 특징패턴 𝜙 추출
4) 몬테카를로(Monte Carlo) 샘플링
- 확률분포를 모를 때 데이터를 이용하여 기대값을 계산하는 데 사용
- 몬테카를로 샘플링은 독립추출만 보장된다면 대수의 법칙(law of large number)에 의해 수렴성 보장
- 참고
몬테카를로 방법과 인공지능 – Sciencetimes
www.sciencetimes.co.kr
velog.io/@luvoatiger/%EC%A0%81%EB%B6%84%EA%B0%92-%EA%B5%AC%ED%95%98%EA%B8%B0
몬테카를로 시뮬레이션 : 함수의 적분값 구하기 (1)
지난 포스팅에서 몬테카를로 시뮬레이션을 이용하면 손으로 계산하기 어려운 작업을 쉽게 할 수 있다고 말씀드렸습니다. 대표적으로 어떤 함수를 수치적으로 계산할 때 응용할 수 있기 때문에,
velog.io
코멘트
오늘은 어제보다 좀 더 심화(?)적인 pandas랑 확률론에 대해 배웠다. 이번주에 수학 강의를 들으면서 느끼는건데 내가 수학을 잘 못 해서 그런건지는 모르겠지만 배운 내용이 딥러닝에 어떻게 적용되는지 잘 와닿지가 않는다. 학교에서도 선형대수랑 통계를 살짝 배워서 기본지식은 어느 정도 있긴 한데 잘 연결이 안 되는 것 같다. 근데 피어세션에서 얘기 들어보니까 다른 팀원들도 다 비슷하게 느끼는 것 같아서 위안이 되었다. 관련 자료들을 더 찾아보고 열심히 공부해서 이해해보려고 노력해야겠다.ㅠㅠ
'부스트캠프 AI Tech 1기 [T1209 최보미] > U stage' 카테고리의 다른 글
| Day11 학습정리 - 딥러닝 기초 (0) | 2021.02.01 |
|---|---|
| Day10 학습정리 - 시각화 / 통계학 (0) | 2021.01.29 |
| Day8 학습정리 - Pandas I / 딥러닝 학습방법 이해하기 (0) | 2021.01.27 |
| Day7 학습정리 - 경사하강법 (0) | 2021.01.26 |
| Day6 학습정리 - Numpy / 벡터 / 행렬 (0) | 2021.01.25 |