강의 복습
1. pandas I
더보기
1) pandas
- 구조화된 데이터의 처리를 지원하는 파이썬 라이브러리
- panel data
- numpy와 통합하여 강력한 스프레드시트 처리 기능 제공
- 인덱싱, 연산용 함수, 전처리 함수 등 제공
- 데이터 처리 및 통계 분석 위해 사용
2) series & dataframe
- series: column vector를 표현하는 object
- dataframe: data table 전체를 포함하는 object
- dataframe 생성: {column_name : data}
- dataframe indexing
- loc: index location(인덱스 이름)
- iloc: index position(인덱스 위치)
- dataframe handling
- transpose: df.T
- 값 출력: df.values
- csv 변환: df.to_csv()
- column 삭제: del df[column_name]
3) selection & drop
- 1개의 column 선택: df[column_name]
1개 이상의 column 선택: df[[column_name1, column_name2, ...]] - column 이름 없이 사용하는 index number: row 기준 표시
column 이름과 함께 row index 사용시 해당 column만 - Boolean index: 조건 만족하는 인덱스
- basic: df[column_name][index_num]
loc: df.loc[column_num,index_name]
iloc: df.iloc[column_num, index_num] - index 재설정: df.index = list(range(n))
- data drop: df.drop(index_num)
한 개 이상 drop: df.drop([index_num1, index_num2, ...]) - axis = 1 → column 기준
4) dataframe operations
- series operation: index 기준으로 연산 수행, 겹치는 index가 없을 경우 NaN값으로 반환
- dataframe operation: column과 index 모두 고려
- add, sub, div, mul
- fill_value: 빈 칸 채울 값 지정
- series + dataframe: axis를 기준으로 row broadcasting 실행
5) lambda, map, apply
- pandas의 series type의 데이터에도 map 함수 사용가능
- function 대신 dict, sequence형 자료등으로 대체 가능
- replace: map 함수의 기능중 데이터 변환 기능만 담당
- dataframe: map과 달리 series 전체(column)에 해당 함수 적용
- 입력 값이 series 데이터로 입력받아 handling 가능
- 내장 연산 함수를 사용할 때도 똑같은 효과를 거둘 수 있음
- mean, std 등 사용 가능
- scalar 값 이외에 series값의 반환도 가능
- series 단위가 아닌 element 단우로 함수 적용
- series 단위에 apply를 적용시킬 때와 같은 효과
6) pandas built-in functions
- describe: numeric type 데이터의 요약 정보를 보여줌
- unique: series data의 유일한 값을 list를 반환
- sum: 기본적인 column 또는 row 값의 연산 지원
- sub, mean, min, max, count, median, mad, var 등
- isnull: column 또는 row 값의 NaN(null) 값의 index 반환
- sort-values: column 값을 기준으로 데이터를 정렬
- ascending: 오름차순
- corr, cov, corrwith: 상관계수와 공분산을 구하는 함수
2. 딥러닝 학습방법 이해하기
더보기
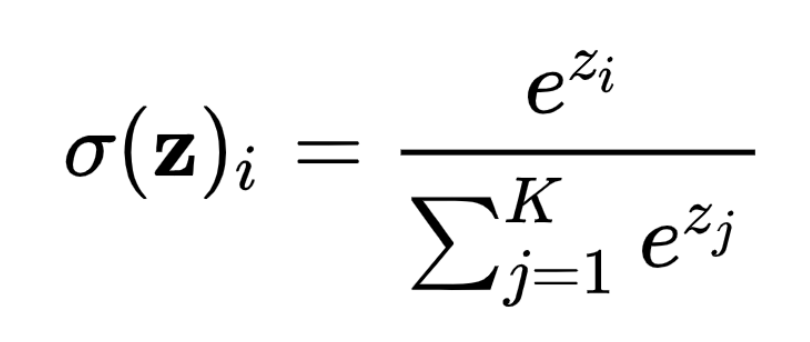
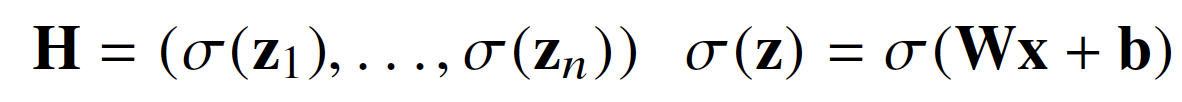
- 비선형모델
- d개의 변수로 p개의 선형모델을 만들어서 p개의 잠재변수 설명
- O: 출력(nxp), X: 데이터(nxd), W: 가중치(dxp), b: 절편(nxp)
→ O = XW + b
2) softmax
- 모델의 출력을 확률로 해석
- 모든 값을 0~1 사이로 정규화, 모든 입력값의 합이 1이 되게 하는 함수
- 분류 문제를 풀 때 선형모델과 소프트맥스 함수를 결합하여 예측
- 추론할 때는 one-hot 벡터로 최대값을 가진 주소만 1로 출력하는 연산 사용
- 왜 e를 사용할까?
- 미분하기 쉬움
- softmax는 argmax와 달리 max에 근접한 값들도 출력되며, 이를 이용해 손실을 계산하는 것이 유익
(hardmax는 미분 불가, softmax는 미분 가능) - 차이가 얼마 안 나도 가장 큰 값이 확실하게 구별되게 함(엔트로피 최대화)
왜 softmax 함수에서는 'e'를 쓰는가?
다들 잘 아시겠지만, softmax를 다시한번 간단히 살펴봅시다. Softmax softmax는 입력되는 모든 값을 0과 1 사이의 값으로 normalize하며, 모든 입력값의 합이 1이되게 하는 함수입니다. 그렇다면, 왜 상수
lv99.tistory.com
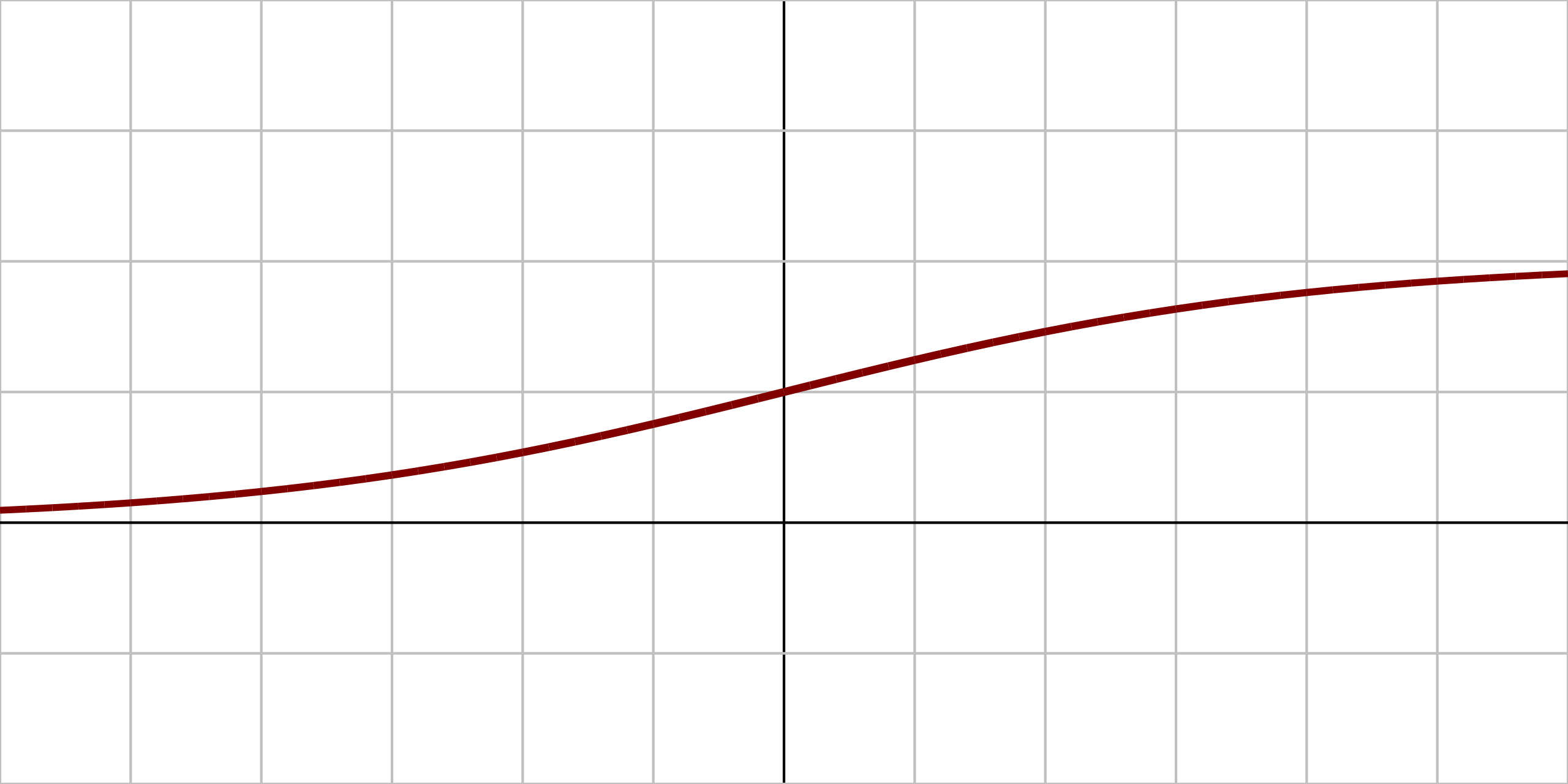
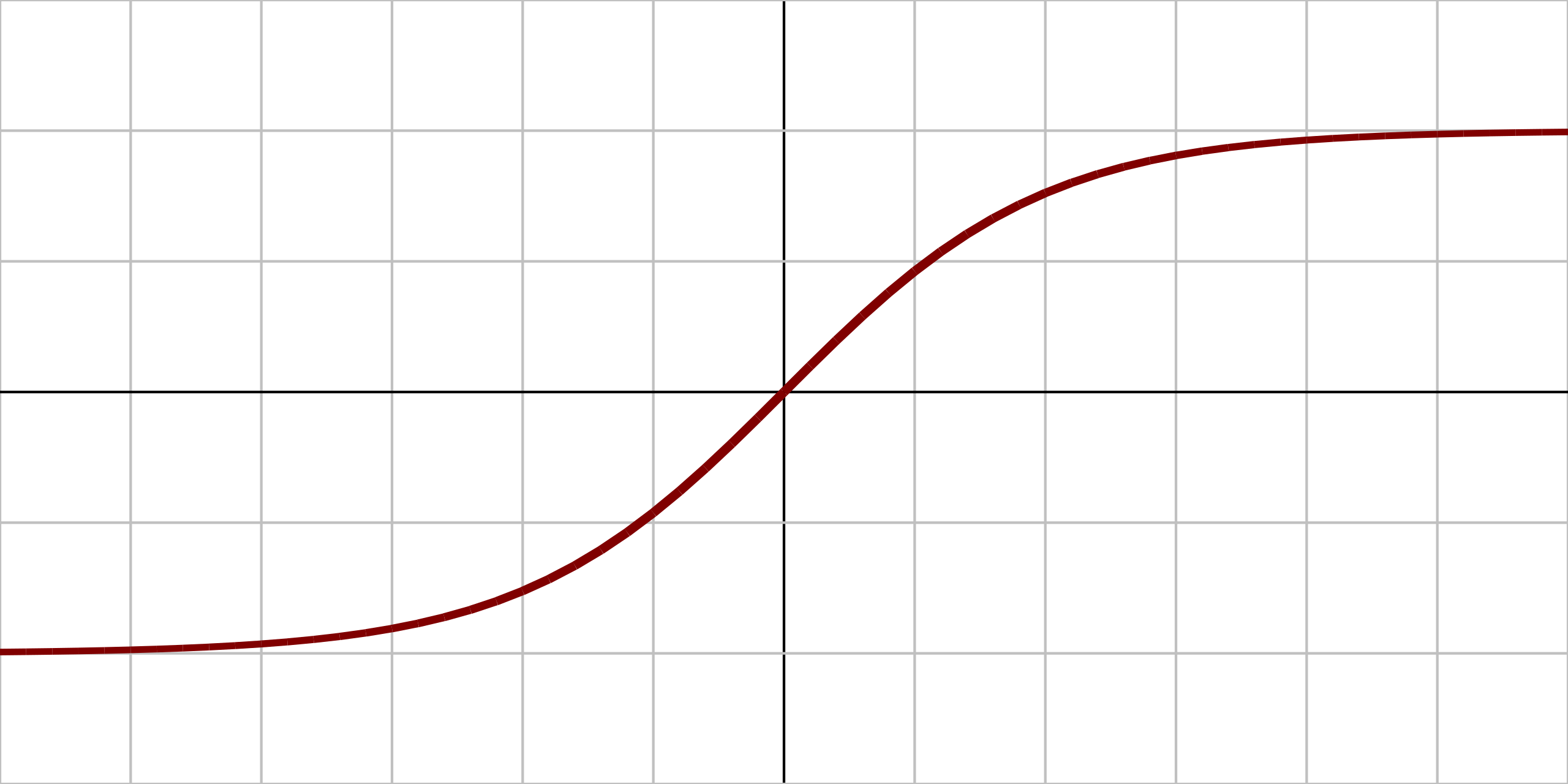
3) 활성함수 (activation function)
- 신경망: 선형모델과 활성함수를 합성한 함수
- 활성함수: R 위에 정의된 비선형 함수
- 활성함수를 쓰지 않으면 딥러닝은 선형모형과 차이가 없음
 |
 |
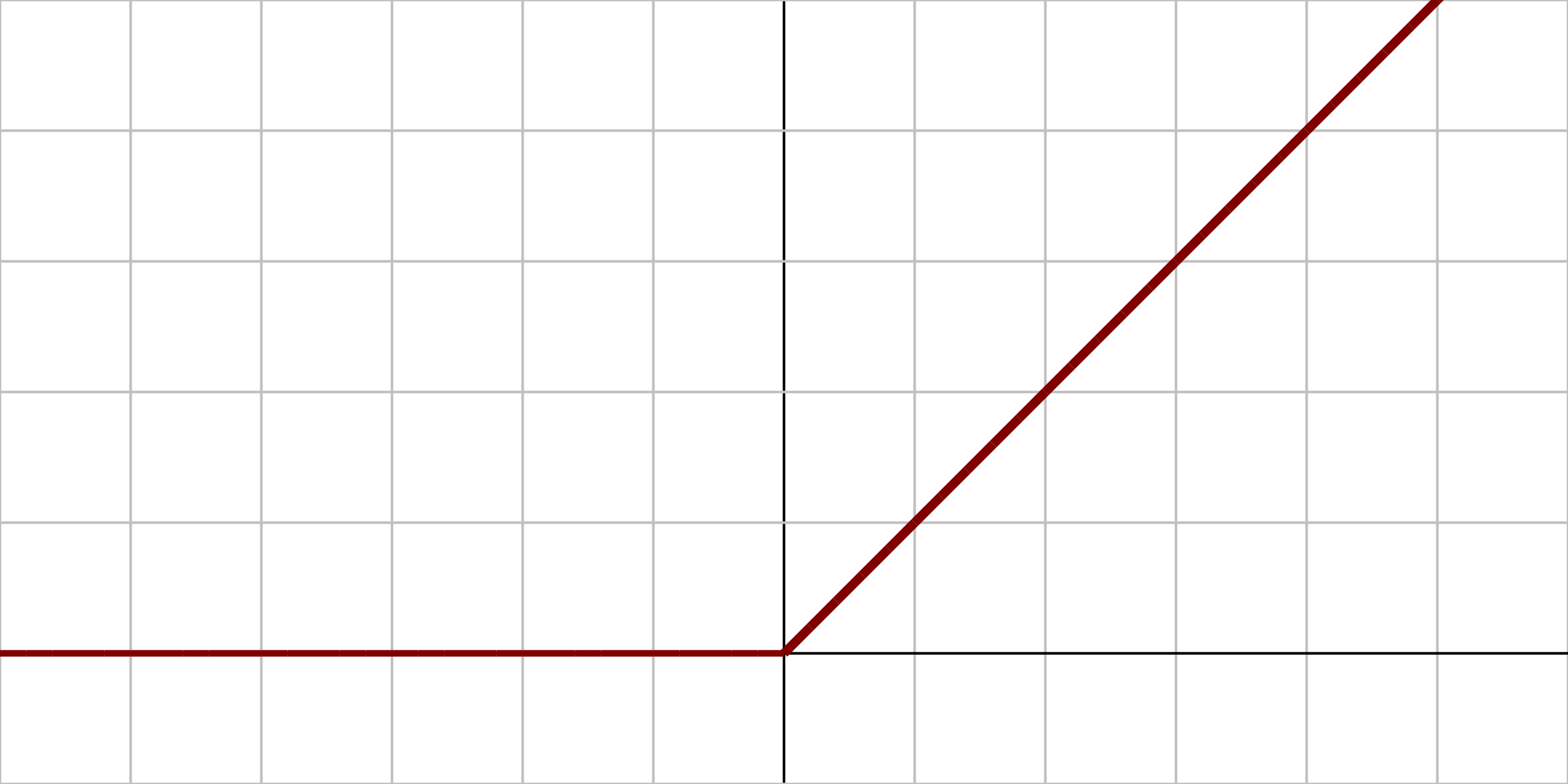 |
| ReLU(x) = max{0, x} |
- 다중(multi-layer) 퍼셉트론(MLP): 신경망이 여러층 합성된 함수
4) 역전파 알고리즘
- 딥러닝은 역전파(backpropagation) 알고리즘을 이용하여 각 층에 사용된 파라미터 학습
- 각 층 파라미터의 그래디언트 벡터는 윗층부터 역순으로 계산
- 역전파 알고리즘은 합성함수 미분법인 연쇄법칙(chain-rule) 기반 자동미분(auto-differentiation) 사용
코멘트
pandas는 데이터 분석하면서 많이 써보긴 했지만 자세히 들어가면 헷갈리는 내용이 좀 있어서 더 공부해야 할 것 같다. 그리고 딥러닝 학습방법 중 softmax 함수에 대해 깊이 공부했다. 뒷부분에 나온 수식이 어려워서 이해가 잘 안 되는데 최대한 이해해보려고 노력해야겠다.
'부스트캠프 AI Tech 1기 [T1209 최보미] > U stage' 카테고리의 다른 글
| Day10 학습정리 - 시각화 / 통계학 (0) | 2021.01.29 |
|---|---|
| Day9 학습정리 - Pandas II / 확률론 (0) | 2021.01.28 |
| Day7 학습정리 - 경사하강법 (0) | 2021.01.26 |
| Day6 학습정리 - Numpy / 벡터 / 행렬 (0) | 2021.01.25 |
| Day5 학습정리 - 파이썬으로 데이터 다루기 (0) | 2021.01.22 |