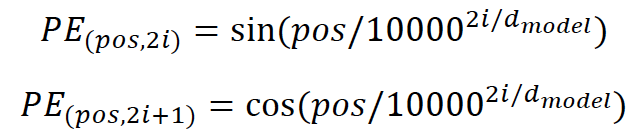: W 행렬을 사용해 Q, K, V를 h개의 lower dimensional space에 mapping시킴
3) Block-Based Model
각 블록은 2개의 sub-layer로 구성
Multi-head attention,
Two-layer feed-forward NN (with ReLU)
각 단계마다 Residual connection, layer normalization 존재 → 𝐿𝑎𝑦𝑒𝑟𝑁𝑜𝑟𝑚(𝑥 + 𝑠𝑢𝑏𝑙𝑎𝑦𝑒𝑟(𝑥))
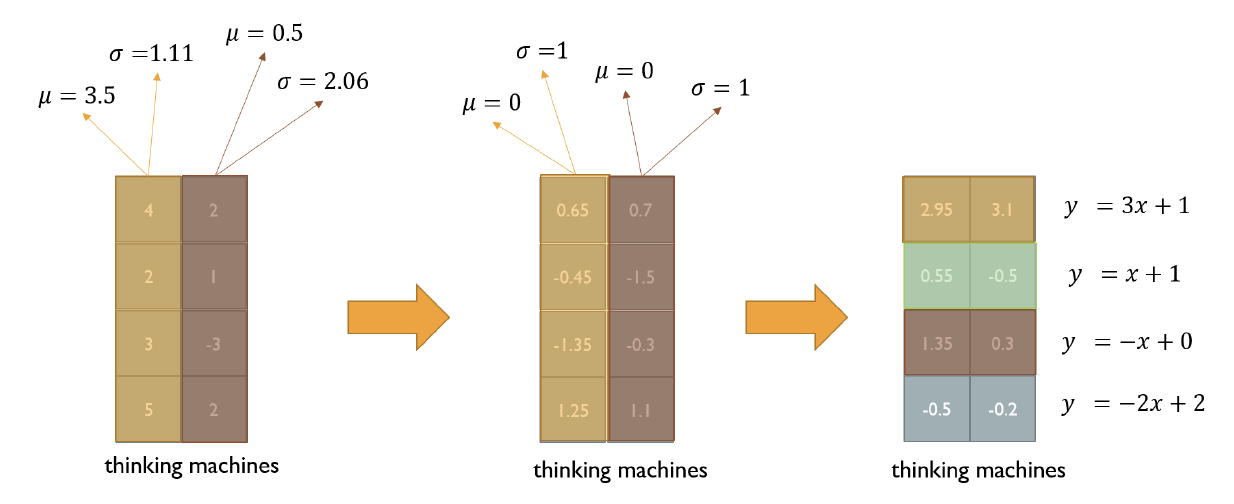
layer normalization
각 word vector들을 mean 0, variance 1이 되도록 표준
각 sequence vector 변환
Positional Encoding
4) Masked Self-Attention
아직 생성되지 않은 단어 접근 방지
피어세션
오늘 피어세션도 코드를 리뷰하는 형식으로 진행됐다. Attention 개념이 이해가 안 됐었는데 팀원들 설명을 듣고 어느정도 이해가 되었다. LSTM에 Attention을 적용할 수 있는지 얘기가 나와서 찾아봤는데 다른 RNN과 마찬가지로 hidden state를 사용해서 적용할 수 있었다.
코멘트
역시 트랜스포머는 어려운 것 같다. 3주차때에도 배웠었는데 그 때 제대로 이해 못 하고 넘어갔더니 이번주에 고생이다. Attention 개념을 잘 이해해야 할 것 같다.