강의 복습
1. Optimization
더보기
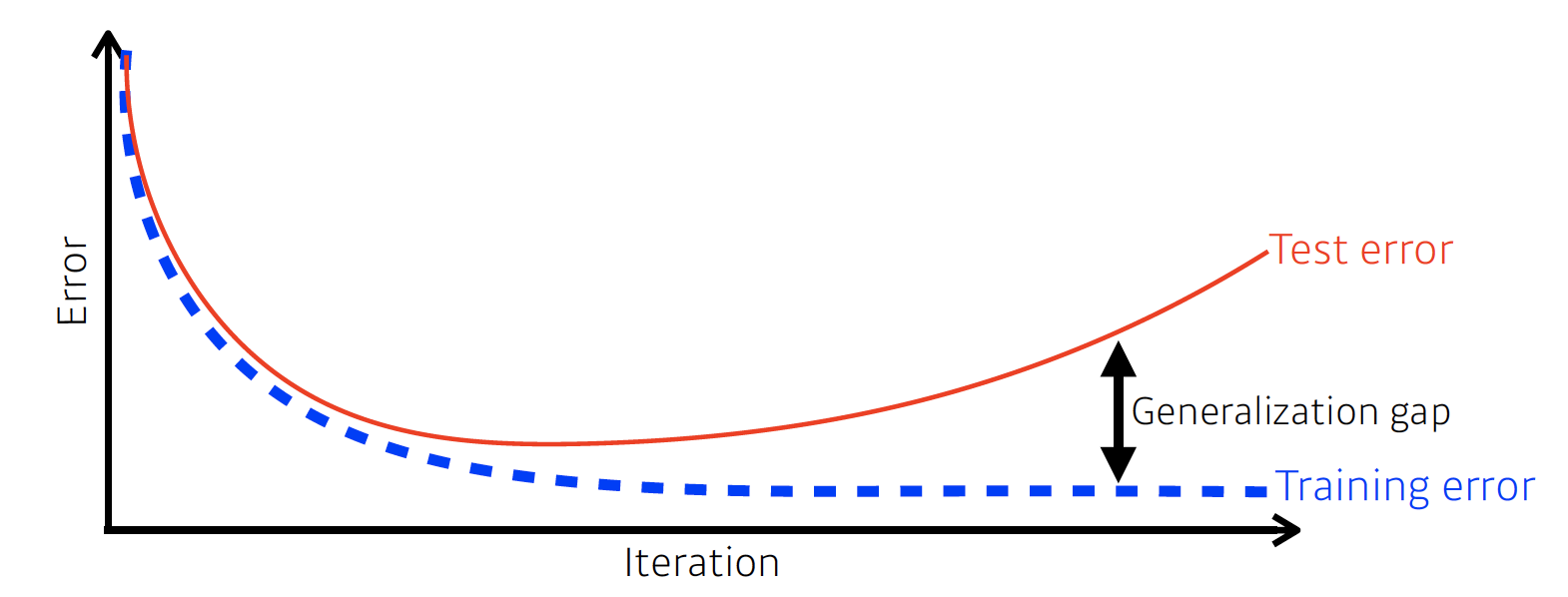





1) Important Concepts in Optimization
- Generalization
- training error와 test error 사이의 차이
- Under-fitting vs Over-fitting
- Cross validation
- k-fold validation: 데이터를 k개로 나눈 후 돌아가면서 k-1개는 training에 사용하고 나머지 1개는 validation으로 사용
- 기타: Leave-p-out, Leave-one-out, Stratified k-fold, Repeated Random Sampling, Nested, TimeSeries 등
- 참고
교차 검증(cross validation)
이번 시간에는 머신러닝에서 평가에 필수적으로 사용되는 교차 검증(cross validation)에 대해서 알아보자....
blog.naver.com
[바람돌이/머신러닝] 교차검증(CV), Cross Validation, K-fold, TimeSeries 등 CV 종류 및 이론
안녕하세요. 오늘은 머신러닝에서 정말 많이 사용되는 교차검증(Cross Validation)에 대해서 정리하겠습...
blog.naver.com
- Bias-variance tradeoff
- Bootstrapping
- 랜덤 샘플링으로 모델을 여러 개 만들어서 예측값들이 얼마나 일치하는지 비교
- Bagging and boosting
- Bagging(Bootstrapping aggregating): 여러 개의 모델을 동시에 학습시킨 후 결과값 평균 냄 (병렬)
- Boosting: 이전 모델에서 잘 학습 안 되는 데이터들에 대해서만 잘 동작하는 모델 만들기를 반복한 후 합침 (직렬)
2) Practical Gradient Descent Methods
- Gradient Descent Methods
- Stochastic gradient descent: 하나의 샘플만 사용하여 gradient 계산
- Mini-batch gradient descent: 데이터 일부만 사용하여 gradient 계산
- Batch gradient descent: 전체 데이터를 사용하여 gradient 계산
- 배치 사이즈
- 배치 사이즈가 크면 sharp minimizers로 수렴 → 모델의 generalization 능력 떨어짐
- 배치 사이즈가 작으면 flat minimizers로 수렴
- 여러 가지 Gradient Descent Methods
- Stochastic gradient descent: learning rate 적당하게 잡기 어려움
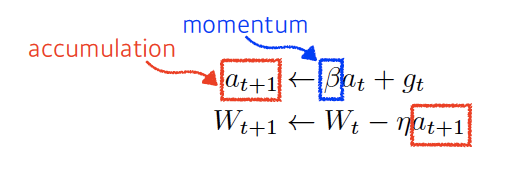
- Momentum: 이전 단계의 정보 활용하여 gradient 계산
- Nesterov accelerated gradient: 현재 방향으로 한 번 이동한 후 그곳에서 gradient 계산
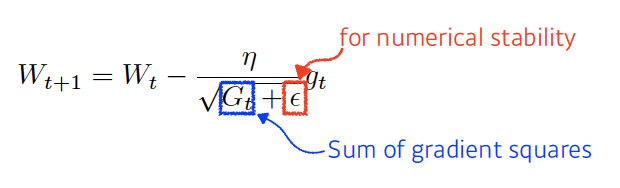
- Adagrad: learning rate 도입, 변화 적은 파라미터는 많이 변화시키고 변화 많은 파라미터는 조금 변화시킴
- Adadelta: Adagrad에서 뒤로 가면 갈수록 G가 계속 커져서 학습이 점점 멈춰지는 문제 해결, learning rate 없음
- RMSprop: Geoff Hinton이 강의에서 제안한 방법, stepsize 들어감
- Adam(Adaptive Moment Estimation): momentum과 gradient squares 같이 활용
|
Stochastic gradient descent |
Momentum |
Nesterov accelerated gradient |
 |
 |
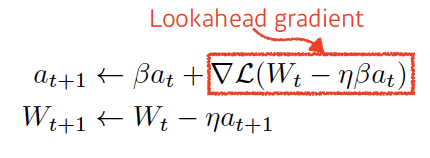 |
|
Adagrad |
Adadelta |
 |
 |
| RMSprop | Adam |
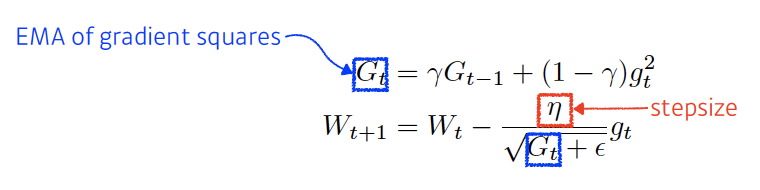 |
 |
3) Regularization
- 학습을 방해해서 모델이 test data에도 잘 적용될 수 있도록 함
- Early stopping: validation data 추가로 필요
- Parameter norm penalty: 네트워크 파라미터가 너무 커지지 않게 함, 부드러운 함수로 만듦
- Data augmentation: 데이터를 회전하고 자르는 등의 가공을 통해 개수를 늘림
- Noise robustness: 중간중간 노이즈 넣음
- Label smoothing: 두 개의 데이터를 섞어서 decision boundary 부드럽게 만듦
- mixup: 두 데이터 부드럽게 섞음
- cutout: 데이터 일부분 잘라냄
- cutmix: 데이터 일부분 잘라낸 후 다른 데이터 붙임
- Dropout: 랜덤으로 몇몇 뉴런을 0으로 바꿈
- Batch normalization: 각 레이어의 parameter 정규화
2. CNN 첫걸음
더보기
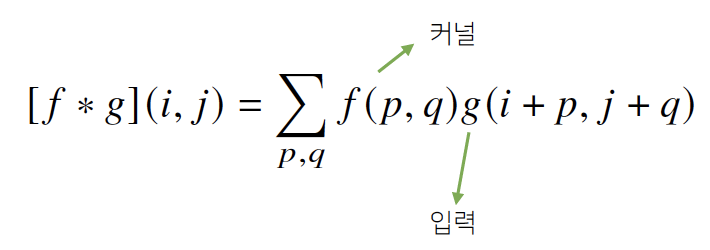
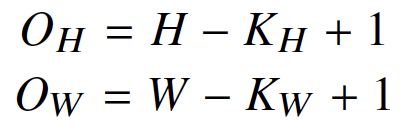



1) Convolution 연산 이해
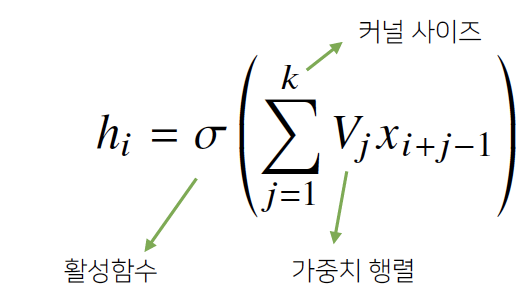
- 다층신경망(MLP): 각 뉴런들이 선형모델과 활성함수로 모두 연결된(fully connected) 구조
Convolution 연산: 커널(kernel)을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조 - Convolution 연산의 수학적 의미: 신호(signal)를 커널을 이용해 국소적으로 증폭 또는 감소시켜서 정보를 추출 또는 필터링
- 커널은 정의역 내에서 움직여도 변하지 않고(translation invariant) 주어진 신호에 국소적(local)으로 적용
| 다층신경망(MLP) | Convolution 연산 |
 |
 |
2) 다양한 차원에서의 Convolution
- 2D-Conv: 커널을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용됨
- 입력 크기를 (H, W), 커널 크기를 (KH, KW), 출력 크기를 (OH, OW)라고 하면 출력 크기는 다음과 같이 계산
- 3차원 Convolution: 2차원 Convolution 3번 적용
3) Convolution 연산의 역전파
- Convolution 연산은 커널이 모든 입력데이터에 공통으로 적용되기 때문에 역전파를 계산할 때도 convolution 연산이 나옴
- 각 커널에 들어오는 모든 그레디언트를 더하면 결국 convolution 연산과 같음
피어세션
오늘부터 다시 발표 스터디를 시작했다. 역시 이렇게 해야 발표 준비하고 다른 팀원들 발표도 들으면서 제대로 공부를 하게 되는 것 같다. 나는 KL Divergence에 대해서 발표했는데 급하게 하느라 강의자료랑 PyTorch 공식문서를 복붙해서 발표자료를 만들었다. 나중에 더 깊이있게 조사해서 추가해야겠다.
코멘트
어제는 강의가 많았는데 오늘은 별로 없어서 비교적 여유로웠다. 오늘 퀴즈에서 한 문제가 오타가 있었는데 그것때문에 고민하다가 그냥 아무렇게 답 써서 제출했더니 틀렸다. 나중에 팀원들한테 물어보고 나서야 오타인 것을 알았다. 그것때문에 오늘 처음으로 퀴즈에서 한 문제 틀렸는데 아깝다ㅠㅠ 물어보고 나서 제출할걸...
'부스트캠프 AI Tech 1기 [T1209 최보미] > U stage' 카테고리의 다른 글
| Day14 학습정리 - Recurrent Neural Networks (0) | 2021.02.04 |
|---|---|
| Day13 학습정리 - Convolutional Neural Networks (0) | 2021.02.03 |
| Day11 학습정리 - 딥러닝 기초 (0) | 2021.02.01 |
| Day10 학습정리 - 시각화 / 통계학 (0) | 2021.01.29 |
| Day9 학습정리 - Pandas II / 확률론 (0) | 2021.01.28 |